How Leadership is Evolving in the Changing Landscape of Modern Work
- Feb 4
- 5 min read
How I got here: building an “artist-first” database without losing the human bit
I’m an interdisciplinary theatre maker / creative technologist, and I tend to move fast. That’s a strength, but it also means I can accidentally create scope creep, skip relationship-building, or build something “clever” that nobody uses.
This project started in a very unglamorous place: an away day with my team where we were reflecting on strengths, friction points, and what we actually need to do our jobs well. A theme kept coming up—care, relationships, artist-centred practice—and the fear underneath it was that admin systems can quietly erode all of that.
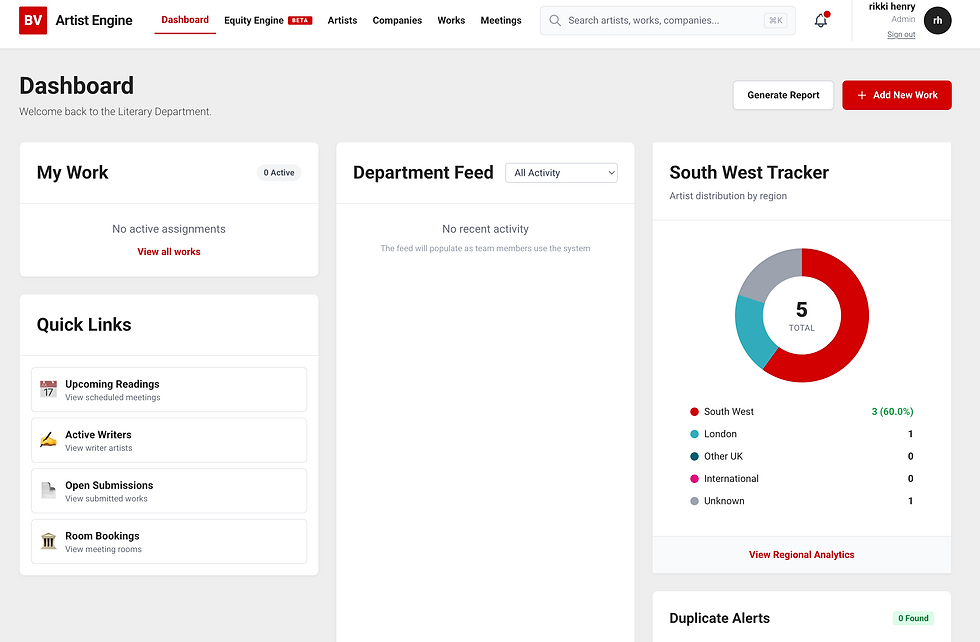
At the same time, I had a concrete deliverable: my line manager needed a dynamic database to track artist progression (writers/directors in the South West). Not a static spreadsheet. Something searchable, interactive, modifiable, intuitive enough that people actually keep it alive.
So I decided to treat it like a real product.
I reframed the problem: it isn’t “a database”, it’s institutional memory
The real issue wasn’t “we don’t have a place to store scripts.”
It was that knowledge about artists lives in:
inboxes,
private notes,
half-remembered conversations,
meeting minutes that aren’t connected to anything,
and people’s heads.
When someone leaves, a lot of context leaves with them. And even when nobody leaves, the team loses time re-finding what we already know. So I shifted the goal from “store stuff” to track relationship and trajectory over time.
That became the spine of what we’re building: a lightweight, artist-centred ARM (Artist Relationship Management) tool—basically a CRM, but shaped around how literary departments actually work.
The methods I pulled in (so I didn’t just “vibe” my way into chaos)
1) “Vibe coding” as a design standard, not a strategy
I want the tool to feel “plug and play”—visually engaging, low friction, not another ugly admin surface. The team values care and relationships; the UI needs to support that, not feel like a punishment.
So vibe coding (to me) means: make it pleasant enough that it gets used, and fast enough that logging doesn’t become a second job.
2) Harper’s LLM workflow as the execution discipline
I used Harper’s post on LLM codegen workflow as a way to force myself (and the assistant) into product clarity:
turn messy reality into a frozen spec.md
generate a prompt plan + to-do list
build in small loops with acceptance criteria
That mattered because I’m a doer. I can ship quickly—but I need guardrails so “quick” doesn’t become “brittle”.
3) Gui Bibeau’s “try this instead” as a stress test
I then brought in a second perspective: Gui Bibeau’s critique of “vibe coding” and the alternative approach (more structured architecture, ticketing, execution discipline). I used it to interrogate whether our plan was actually buildable, or just a nice story.
What I was really doing was triangulating:
my team’s real process + values,
Harper’s spec-driven approach,
Gui’s architecture discipline.
The key product decisions I forced myself to make (so the build didn’t drift)
I didn’t want a vague “build a CRM” prompt. I wanted a set of hard decisions that define the product.
Data capture: stop “data rot”
I chose both:
quick add (minimal friction)
and email-forward capture (so logging can be invisible)
The whole point is: if it’s hard to enter, it won’t be entered.
Triage: gatekeeper push system
We decided triage should be controlled: an Admin (Ben/Nancy) pushes work out to readers, rather than chaos in an unassigned pool. This mirrors how power and responsibility actually works in the department.
Privacy: a “private layer”
We need a place for sensitive notes that shouldn’t be broadly visible. That isn’t a nice-to-have—it’s fundamental to keeping relationships ethical and the tool safe to use.
Scripts: direct upload (version truth)
I changed my mind here after thinking about the reality of drafts and context. Linking out to SharePoint/Drive is convenient, but it’s also fragile. I want the exact draft we read to be permanently attached to that work/artist record. Otherwise the database becomes unreliable.
Search: metadata now, deeper later—but strict IP rules
I chose metadata-only search for v1, with forethought for more advanced search later. But I’m extremely wary of artist work being exposed to AI training. If we ever do deeper search, it needs to be done in a way that protects the work (closed systems, explicit controls).
Verdicts: separate work outcomes from artist status
We clarified that decisions happen at multiple levels:
a Work Verdict (e.g., pass to programming, archive)
an Artist Status (e.g., scouting, active relationship)
Those are not the same thing, and the system should reflect that nuance.
Deletion policy: archive only
No hard deletes. This is about institutional memory. If we “clean up” too aggressively, we lose the point of building it.
The most “institutional” thing I embedded: our actual evaluation framework + meeting rhythm
This wasn’t a generic CRM project. It’s bound to real practice.
MAGIC framework (Programming Reading Guidelines)
I uploaded our internal “Programming Reading Guidelines” because I wanted the tool to reflect how we actually judge work, not some generic star rating.
MAGIC isn’t just an acronym; it’s a structured set of prompts and ways of thinking that need to exist as literal form fields, helper text, and review structure.
The meeting cycle
I anchored the database to the real flow of decisions:
Literary → Programming → Producing
So the system isn’t just “store artists”, it’s “show me what’s coming up, what we’re reading, why, who is assigned, what we decided, and what happens next.”
The turning point: I hit the handover-quality wall
This is where I got strict.
I realised that if I’m using another LLM to code (Cursor/Aider/Replit), the spec can’t be “pretty good”. It has to be mechanically explicit—because any ambiguity will be filled with hallucination.
The MAGIC framework issue was the perfect example: if the exact prompts aren’t embedded, the developer/LLM will invent them, and that undermines the whole reason we’re doing this (institutional integrity + consistency).
So I demanded a more senior-level output:
page-upon-page spec
acceptance criteria
negative constraints (“do not do X”)
edge cases
permission rules
audit trail logic
and a granular prompt plan that a coding agent can follow without improvising.
That’s why I decided the task should move to a more capable agent setup (DeepAgent): I need a hallucination-resistant build package, not a motivational outline.
Where I am now
I’ve:
clarified the real-world need,
anchored the tool in our processes,
made the uncomfortable product decisions,
chosen a sensible stack (Next.js + Supabase),
and learned that the real work is in the spec quality, not the tech.
The next phase is execution: turning all this into a locked spec + ticket plan that’s so explicit it’s boring—because boring is what ships.



Comments